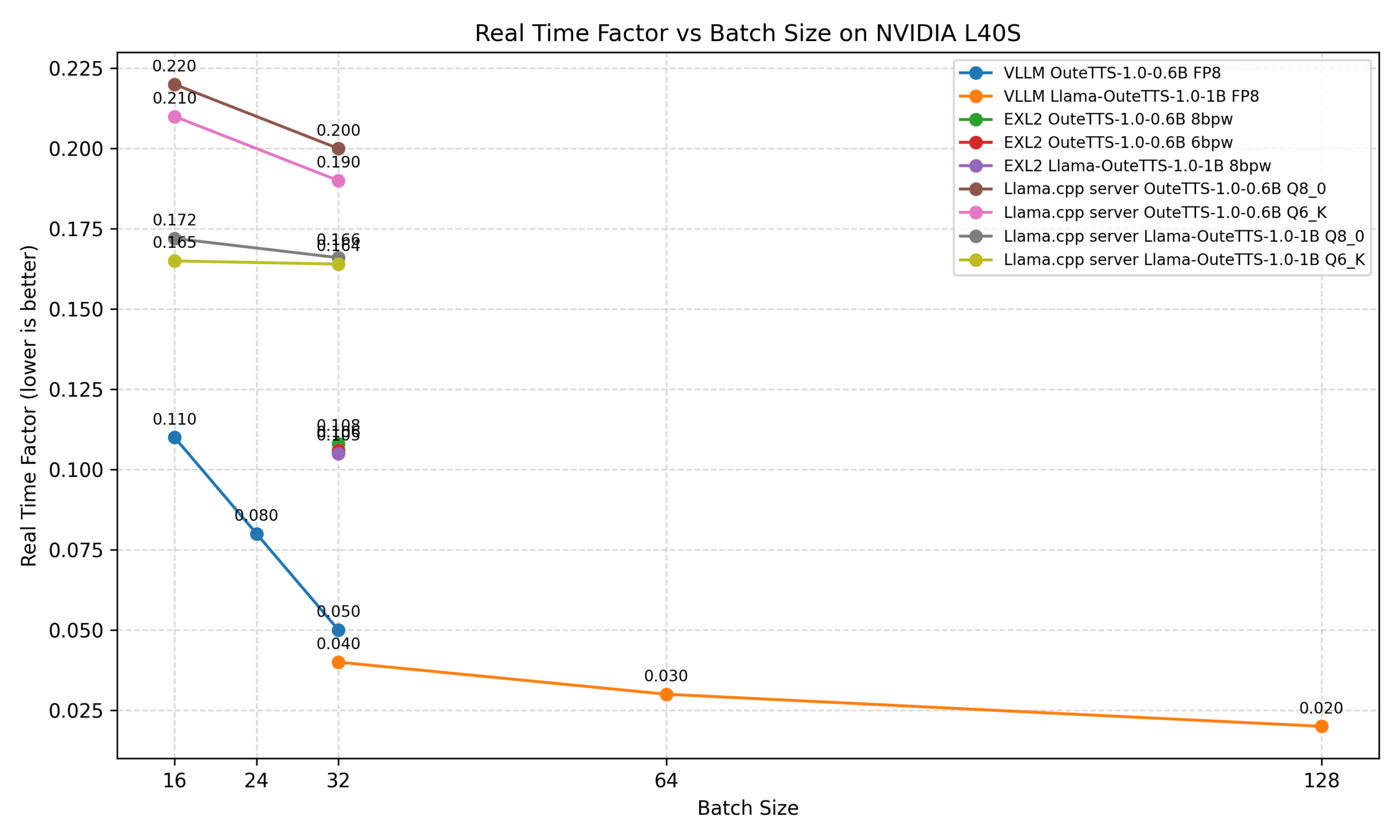
Llasa-3B
综合介绍
Llasa-3B是由香港科技大学(HKUST)的音频研究团队HKUSTAudio开发的一款先进的文本转语音(TTS)模型。该模型的基础是Meta公司的Llama 3.2大型语言模型,通过创新的方法将语音合成任务转化为一种特殊的语言处理任务。具体来说,Llasa-3B利用XCodec2编码器将音频文件转换成一系列“语音词元(token)”,然后像处理文字一样处理这些词元,从而生成语音。这一设计使得大型语言模型领域的现有技术,如模型压缩、推理加速和微调等,都有可能被应用于语音合成领域。
Llasa-3B经过了长达25万小时的中英双语语音数据训练,因此能够生成非常自然、逼真且富有情感的人声。 它不仅支持直接从文本生成语音,还具备强大的“声音克隆”功能,仅需一小段音频作为提示,就能模仿该声音的音色、风格和韵律来生成新的语音内容。 模型能够表现出开心、难过、生气甚至耳语等多种情感,极大地提升了合成语音的真实感和表现力。 目前,该模型以开源权重的方式发布,但其cc-by-nc-4.0许可证禁止免费商业使用。
功能列表
- 高质量文本转语音(TTS):输入中文或英文文本,模型能够生成清晰、自然、媲美真人的语音。
- 语音克隆(零样本TTS):用户可以提供一小段(5-10秒)目标语音样本,模型将模仿该样本的音色、口音和韵律来朗读新的文本内容。
- 双语支持:模型在大量的中文和英文数据集上进行了训练,能够流利地处理这两种语言的语音合成。
- 情感表达:能够根据文本内容生成带有不同情感色彩的语音,例如高兴、悲伤或愤怒,甚至可以生成轻声耳语的效果。
- 与LLaMA框架兼容:作为基于LLaMA的模型,它可以无缝集成到现有的LLM工作流中,便于开发者进行二次开发和微调。
- 多种模型规模:提供10亿、30亿等不同参数规模的版本,并计划推出80亿参数的版本,以适应不同的硬件和性能需求。
- 开源权重:模型权重对社区开放,方便学术研究和非商业性质的应用探索。
使用帮助
Llasa-3B是一个需要通过编程代码来使用的深度学习模型,用户需要在具备合适硬件(特别是NVIDIA GPU)的计算机上配置Python环境来运行它。以下是详细的安装和使用流程。
第一步:环境准备
运行Llasa-3B对硬件有一定要求,尤其是显存(VRAM)。建议使用配备至少8GB显存的NVIDIA GPU以获得流畅体验。
- 安装Python和Conda:为了避免不同项目之间的软件库冲突,推荐使用Conda来创建独立的虚拟环境。请确保你的系统上已经安装了Miniconda或Anaconda。同时,Llasa-3B与Python 3.9版本兼容性较好。
- 创建Conda虚拟环境:打开终端(在Windows上是Anaconda Prompt),输入以下命令来创建一个名为
llasa_tts的新环境并激活它:conda create -n llasa_tts python=3.9 -y conda activate llasa_tts - 安装PyTorch:PyTorch是运行Llasa-3B所必需的深度学习框架。请访问PyTorch官网,根据你的操作系统和CUDA版本选择合适的命令进行安装。例如,一个常见的安装命令如下:
pip install torch torchvision torchaudio - 安装依赖库:Llasa-3B依赖几个关键的Python库,包括用于模型加载的
transformers、用于音频处理的soundfile以及核心的语音编码器xcodec2。执行以下命令安装:pip install transformers soundfile pip install xcodec2==0.1.3
第二步:基础功能——文本转语音
这是模型最基本的功能,将一段文字直接转换成语音文件。
- 编写Python脚本:创建一个名为
text_to_speech.py的Python文件,将以下代码复制进去。这段代码将加载Llasa-3B模型和XCodec2编码器,然后将指定的文本转换为语音并保存为.wav文件。import torch import soundfile as sf from transformers import AutoTokenizer, AutoModelForCausalLM from xcodec2.modeling_xcodec2 import XCodec2Model # 检查是否有可用的GPU,如果没有则使用CPU device = 'cuda' if torch.cuda.is_available() else 'cpu' print(f"正在使用 {device} 设备") # --- 1. 加载模型和分词器 --- print("正在加载Llasa-3B模型...") llasa_model_id = 'HKUSTAudio/Llasa-3B' tokenizer = AutoTokenizer.from_pretrained(llasa_model_id) model = AutoModelForCausalLM.from_pretrained(llasa_model_id) model.eval().to(device) print("正在加载XCodec2声码器模型...") codec_model_id = "HKUSTAudio/xcodec2" codec_model = XCodec2Model.from_pretrained(codec_model_id) codec_model.eval().to(device) # --- 2. 定义输入文本 --- # 你可以修改这里的文本内容 # 英文示例 input_text = 'Dealing with family secrets is never easy. Yet, sometimes, omission is a form of protection.' # 中文示例 # input_text = '突然,身边一阵笑声。我看着他们,意气风发地挺直了胸膛,甩了甩那稍显肉感的双臂,轻笑道:"我身上的肉,是为了掩饰我爆棚的魅力!"' # --- 3. 准备模型输入格式 --- # 模型需要特定的格式来区分普通文本和待生成的语音指令 formatted_text = f"<|TEXT_UNDERSTANDING_START|>{input_text}<|TEXT_UNDERSTANDING_END|>" chat = [ {"role": "user", "content": "Convert the text to speech:" + formatted_text}, {"role": "assistant", "content": "<|SPEECH_GENERATION_START|>"} ] input_ids = tokenizer.apply_chat_template( chat, tokenize=True, return_tensors='pt', add_generation_prompt=True # continue_final_message 在一些旧版本中被使用 ).to(device) # 获取语音生成的结束标记 speech_end_id = tokenizer.convert_tokens_to_ids('<|SPEECH_GENERATION_END|>') # --- 4. 生成语音词元 (Token) --- print("正在生成语音...") with torch.no_grad(): outputs = model.generate( input_ids, max_length=2048, # 模型训练时使用的最大长度 eos_token_id=speech_end_id, do_sample=True, top_p=0.95, # 推荐参数,用于生成更稳定的结果 temperature=0.9 # 控制输出的随机性 ) # --- 5. 解码并保存为音频文件 --- # 从输出中提取生成的语音词元ID generated_ids = outputs[0][len(input_ids[0]):-1] # 将词元ID转换为语音ID整数 speech_tokens_str = tokenizer.batch_decode(generated_ids, skip_special_tokens=True) speech_ids = [int(token[4:-2]) for token in speech_tokens_str if token.startswith('<|s_') and token.endswith('|>')] if not speech_ids: print("警告:未能生成任何有效的语音词元。请检查输入文本或模型设置。") else: speech_tensor = torch.tensor(speech_ids).to(device).unsqueeze(0).unsqueeze(0) # 使用XCodec2解码器将语音ID转换为波形数据 gen_wav = codec_model.decode_code(speech_tensor) # 保存为WAV文件 output_filename = "generated_speech.wav" sf.write(output_filename, gen_wav[0, 0, :].cpu().numpy(), 16000) print(f"语音已成功生成并保存为 {output_filename}") - 运行脚本:在激活了
llasa_tts环境的终端中,执行以下命令:python text_to_speech.py脚本运行结束后,如果一切顺利,你会在当前目录下找到一个名为
generated_speech.wav的音频文件。
第三步:特色功能——使用语音提示(语音克隆)
这是Llasa-3B的强大功能,可以模仿给定音频的音色来生成新的语音。
- 准备提示音频:你需要一个
.wav格式的音频文件作为声音样本,时长建议在5到10秒之间。音频的采样率必须是16kHz。你可以使用任何音频编辑软件(如Audacity)来转换你的音频文件。将这个文件命名为prompt.wav并放在与Python脚本相同的目录下。 - 编写Python脚本:创建一个名为
voice_cloning.py的文件,并复制以下代码。import torch import soundfile as sf from transformers import AutoTokenizer, AutoModelForCausalLM from xcodec2.modeling_xcodec2 import XCodec2Model import os # --- 环境和模型加载 (与之前相同) --- device = 'cuda' if torch.cuda.is_available() else 'cpu' print(f"正在使用 {device} 设备") print("正在加载Llasa-3B模型...") llasa_model_id = 'HKUSTAudio/Llasa-3B' tokenizer = AutoTokenizer.from_pretrained(llasa_model_id) model = AutoModelForCausalLM.from_pretrained(llasa_model_id) model.eval().to(device) print("正在加载XCodec2声码器模型...") codec_model_id = "HKUSTAudio/xcodec2" codec_model = XCodec2Model.from_pretrained(codec_model_id) codec_model.eval().to(device) # --- 1. 定义输入和加载提示音频 --- prompt_audio_path = "prompt.wav" if not os.path.exists(prompt_audio_path): raise FileNotFoundError(f"错误:未找到提示音频文件 '{prompt_audio_path}'。请将一个16kHz采样率的WAV文件放在此目录。") prompt_wav, sr = sf.read(prompt_audio_path) if sr != 16000: raise ValueError(f"错误:提示音频的采样率必须是16kHz,当前为{sr}Hz。") prompt_wav = torch.from_numpy(prompt_wav).float().unsqueeze(0).to(device) # 要生成的目标文本 target_text = '突然,身边一阵笑声。我看着他们,意气风发地挺直了胸膛,甩了甩那稍显肉感的双臂,轻笑道:"我身上的肉,是为了掩饰我爆棚的魅力!"' # --- 2. 将提示音频编码为语音词元 --- print("正在编码提示音频...") with torch.no_grad(): prompt_tokens_ids = codec_model.encode_code(input_waveform=prompt_wav)[0, 0, :] # 将语音ID转换为模型可识别的词元字符串 prompt_speech_tokens = [f"<|s_{i}|>" for i in prompt_tokens_ids.tolist()] # --- 3. 准备模型输入 --- # 在这个模式下,模型同时接收文本和提示音的词元 formatted_text = f"<|TEXT_UNDERSTANDING_START|>{target_text}<|TEXT_UNDERSTANDING_END|>" chat = [ {"role": "user", "content": "Convert the text to speech:" + formatted_text}, {"role": "assistant", "content": "<|SPEECH_GENERATION_START|>" + "".join(prompt_speech_tokens)} ] input_ids = tokenizer.apply_chat_template( chat, tokenize=True, return_tensors='pt', add_generation_prompt=True ).to(device) speech_end_id = tokenizer.convert_tokens_to_ids('<|SPEECH_GENERATION_END|>') # --- 4. 生成语音 --- print("正在生成克隆语音...") with torch.no_grad(): outputs = model.generate( input_ids, max_length=2048, eos_token_id=speech_end_id, do_sample=True, top_p=0.95, temperature=0.9 ) # --- 5. 解码并保存 --- # 提取生成的部分,不包含输入的提示音部分 generated_ids = outputs[0][input_ids.shape[1]:] # 将词元ID转换为语音ID整数 speech_tokens_str = tokenizer.batch_decode(generated_ids, skip_special_tokens=True) speech_ids = [int(token[4:-2]) for token in speech_tokens_str if token.startswith('<|s_') and token.endswith('|>')] if not speech_ids: print("警告:未能生成任何有效的语音词元。") else: # 将提示音和新生成的语音ID合并,以解码出完整的音频 full_speech_ids = torch.cat([prompt_tokens_ids, torch.tensor(speech_ids, device=device)]) full_speech_tensor = full_speech_ids.unsqueeze(0).unsqueeze(0) gen_wav = codec_model.decode_code(full_speech_tensor) output_filename = "cloned_speech.wav" sf.write(output_filename, gen_wav[0, 0, :].cpu().numpy(), 16000) print(f"克隆语音已成功生成并保存为 {output_filename}") - 运行脚本:确保
prompt.wav文件已放置好,然后在终端中运行:python voice_cloning.py运行结束后,你将得到一个
cloned_speech.wav文件,其音色会模仿prompt.wav。
应用场景
- 内容创作播客制作者、视频创作者或有声书出版商可以使用Llasa-3B快速生成高质量的旁白和配音。其情感表达能力可以使内容更具吸引力,语音克隆功能则可以用于创造独特的角色声音或保持旁白的一致性。
- 个性化虚拟助手开发者可以利用Llasa-3B为智能助手或应用程序创建独特的、听起来自然的语音。用户甚至可以上传自己的声音样本,让虚拟助手的发音与自己或指定人物的声音一样,提供高度个性化的交互体验。
- 辅助功能工具对于有阅读障碍或视力障碍的用户,Llasa-3B可以作为一个强大的朗读工具,将网页、电子书或文档等文本内容转换为清晰、易于理解的语音,提升信息获取的便利性。
- 教育和语言学习在语言学习软件中,可以利用该模型提供标准、地道的中英文发音范例。其自然的语调和韵律有助于学习者更好地掌握语言的口语表达。
- 游戏和娱乐游戏开发者可以使用Llasa-3B为游戏角色(NPC)生成大量的对话语音,而无需雇佣大量配音演员,从而节省成本并丰富游戏世界。其语音克隆能力也可用于创造多样化的角色声音。
QA
- 问:使用Llasa-3B需要付费吗?答:Llasa-3B模型本身是开源的,可以免费下载和使用。但是,它的许可是
cc-by-nc-4.0,这意味着它禁止被用于任何免费的商业用途。如果你希望将其用于商业产品,需要遵守许可证的规定或联系开发团队获取商业授权。 - 问:我可以在没有高端显卡的电脑上运行Llasa-3B吗?答:在没有GPU或GPU显存不足(低于6.5GB)的电脑上运行Llasa-3B会非常缓慢,甚至可能因内存不足而失败。 对于本地资源不足的用户,可以考虑使用云服务平台(如Hugging Face Spaces、Google Colab或Replicate等)提供的在线Demo或GPU计算资源来体验模型。
- 问:Llasa-3B支持除了中文和英文之外的其他语言吗?答:目前,Llasa-3B主要在中英双语数据上进行训练,因此在这两种语言上表现最好。 虽然它可能对其他语言的文本有一定处理能力,但效果无法保证。
- 问:语音克隆功能需要多长时间的音频样本?答:该模型具备零样本(zero-shot)语音克隆能力,理论上仅需几秒钟的清晰语音样本(推荐5-10秒)即可实现有效的音色模仿。 音频样本的质量(如清晰度、无背景噪音)对克隆效果有很大影响。
- 问:生成的语音听起来很奇怪或不稳定怎么办?答:根据开发团队的建议,可以尝试调整
generate函数中的top_p和temperature参数。将top_p设置为0.95,temperature设置为0.9可能会产生更稳定的结果。 此外,确保输入的文本没有特殊字符或格式问题,提示音频质量要高,这些都可能影响最终效果。